I don't use Spotify or any other streaming platform for listening to music. Some call it old habits, some call it needless effort, but I'm very used to downloading MP3 files over the internet and putting them in a folder on my phone then using the whatever default media player I have installed. However, for a couple of years, I have been following a better and automated approach for taking my music offline and feeling a bit less like I'm in a consumerism bubble.
While I'm working, I usually have YouTube open on one tab playing music. So I created a separate YouTube account/channel dedicated to creating playlists. In my workflow, after saving what I listen to a playlist, the next step would be downloading these tracks as MP3 and transferring them to my phone. But before I dive into details about how I'm doing that, there are some questions that I would like to answer.
Q: If you already have your music on YouTube, why not use YouTube on your phone?
A: I would like to be able to listen to music when I'm offline (i.e. when there is no internet connection).
Q: Have you heard of YouTube Music?
A: Yes, is it free?
Q: But YouTube is full of ads, isn't it annoying?
A: I have an AdBlock extension.
Q: You are using YouTube at the end of the day. Doesn't it conflict with what you are trying to achieve while saying "move away from streaming platforms"?
A: Yes, it is partially true. But I would like to discover new artists/music so I need a "source" for that. I'm only taking the good parts of YouTube (e.g. its algorithm) and self-hosting the rest.
Q: What about supporting the artists?
A: Streaming is not the only way to support an artist.
Q: Why are you doing this?
A: I would like to keep the hard copy of the media that I want to consume. I don't want to leave everything to "the cloud" and I find that wrong. Also, in some cases, I have witnessed the removal of the music that I like since I follow rather obscure artists. Plus, having physical files is great for collecting/archiving purposes. TL;DR: I love files.
Q: Is this a meme?
A: No, check out "Boomer Yells at Cloud Computing" by Luke Smith.
Overview
- Create playlists on YouTube
- Download MP3 from YouTube periodically
- Synchronize the MP3 files over to your phone
- Use an open source MP3 player to listen to music
Things that you need
- A home server (base of operations)
- I have a Raspberry Pi 4 running Arch Linux ARM
- An external drive (for storing MP3 files)
- I have a 2.5" external hard disk drive with 1TB of storage connected to my Raspberry Pi
- A YouTube account (for creating playlists)
- youtube-dl (GitHub) (for downloading playlists)
- Syncopoli (GitLab) (for
rsync'ing MP3 files to an Android phone) - Music Player GO (GitHub) (for actually listening to music)

Setting up the storage

In my case, I just connected my external hard drive to Raspberry Pi and updated /etc/fstab to mount it on boot.
# Static information about the filesystems.
# See fstab(5) for details.
# <file system> <dir> <type> <options> <dump> <pass>
/dev/sda1 /mnt/tera exfat rw,user,uid=1000,umask=007,exec 0 0So it will be mounted to /mnt/tera on boot. Note that I have HPFS/NTFS/exFAT filesystem on this drive and your situation might be different.
Next step is creating a separate directory on this drive (since I have some other files) and symlinking it to somewhere more convenient.
mkdir -p /mnt/tera/backups/YouTube/
ln -s /mnt/tera/backups/ /backupsSo that I will be able to use /backups as a directory pointing to my backups in the drive. Later on, I will be downloading the MP3 files to /backups/YouTube directory.
Creating a YouTube account
I like having things separated so I suggest having a YouTube channel just for creating playlists. You can create these playlists as public or private since youtube-dl supports both. You can use --cookies argument for specifying a cookie if needed.
Then you can start creating playlists as you are discovering new music/artists thanks to the great algorithm of YouTube!
Downloading playlists
In order to keep track of the downloaded videos (tracks), we will need to use download-archive feature of youtube-dl.
With this feature you should initially download the complete playlist with --download-archive /path/to/download/archive/file.txt that will record identifiers of all the videos in a special file. Each subsequent run with the same --download-archive will download only new videos and skip all videos that have been downloaded before. Note that only successful downloads are recorded in the file.
So running the following command will suffice our needs and download the each playlist in their designated folder:
$ youtube-dl \
--socket-timeout 15 \
--ignore-errors \
--extract-audio \
--audio-format mp3 \
--audio-quality 0 \
--add-metadata \
--metadata-from-title="%(artist)s - %(title)s" \
--embed-thumbnail \
--download-archive ".archive" \
--output '%(playlist)s/%(title)s.%(ext)s' \
"https://www.youtube.com/channel/<channel_id>/playlists"Each directory will contain the MP3 files from that playlist:
$ ls patapon/ sonic/
patapon/:
"09. Moudamepon's Theme - Disk 2 - Patapon Complete Soundtrack.mp3"
'Patapon Soundtrack - 10 ビビリッチのテーマ.mp3'
sonic/:
'Burning Depths - Sonic & All-Stars Racing Transformed [OST].mp3'
'Disquieting Shadow - Sonic Heroes [OST].mp3'List of video IDs will be stored in .archive:
youtube Hcrkbtcjoi4
youtube Hn1vLFDm98I
youtube _pUL7u-mYqA
...Also, I wanted to keep track of what I have added to this list so I've used a git repository. Here is the final script:
#!/usr/bin/env bash
set -e
cd /backups/YouTube/
youtube-dl \
--socket-timeout 15 \
--ignore-errors \
--extract-audio \
--audio-format mp3 \
--audio-quality 0 \
--add-metadata \
--metadata-from-title="%(artist)s - %(title)s" \
--embed-thumbnail \
--download-archive ".archive" \
--output '%(playlist)s/%(title)s.%(ext)s' \
"https://www.youtube.com/channel/<channel_id>/playlists"
git add .archive
git -c user.name="ytdl" \
-c user.email="ytdl@git" \
commit -m "upd: v$(date +'%s')"Setting up the cronjob
Now we will need to create a cronjob for periodically downloading the playlists using the previous script.
$ crontab -e # edit user's crontab
$ crontab -l # list cronjobs
0 0 * * 0 /backups/YouTube/fetch.shThis cronjob will run weekly and download the playlists.
Here is what git log will look like after you let it run for a couple of weeks:
commit 0abef26b3dbef43f15e0172190b2e802d38ed5c3
Author: ytdl <ytdl@git>
Date: Sun May 22 02:54:50 2022 +0300
upd: v1653177290
commit ef7ec0d63616d82ce3cc942e2edddf1452063208
Author: ytdl <ytdl@git>
Date: Sun May 15 00:48:31 2022 +0300
upd: v1652564911
commit 0c0af6ea38c8f07990d7954f6f69ab592ff49c38
Author: ytdl <ytdl@git>
Date: Sun May 8 00:32:26 2022 +0300
upd: v1651959146Syncing the files
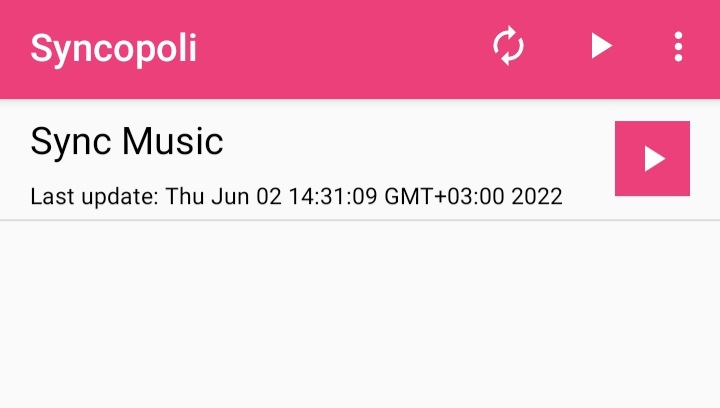
I'm using Syncopoli to rsync(1) files over to my phone. It is a really simple yet effective application. Some parts are still WIP but you can head to the repository and contribute if you're interested.
Main screen:
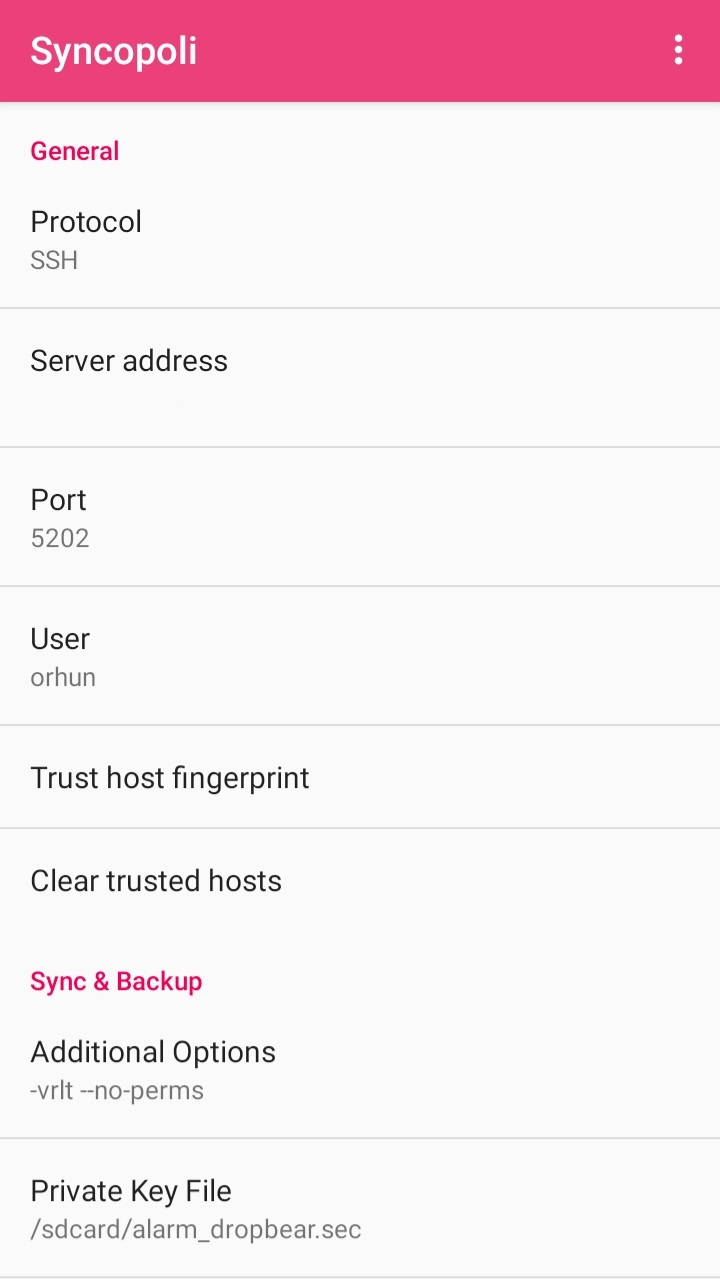
Settings:
I had a couple of issues with my settings so it is always a good idea to monitor the SSH connection attempts on your server while trying out Syncopoli:
$ journalctl -f -u sshdIn my case, this command greatly helped me to spot issues like the following:
fatal: Timeout before authentication for 192.168.1.37 port 60044
error: maximum authentication attempts exceeded for orhun from 192.168.1.37 port 60038 ssh2 [preauth]
Also, you can use Logcat Reader to see which rsync commands are being run and what has failed.
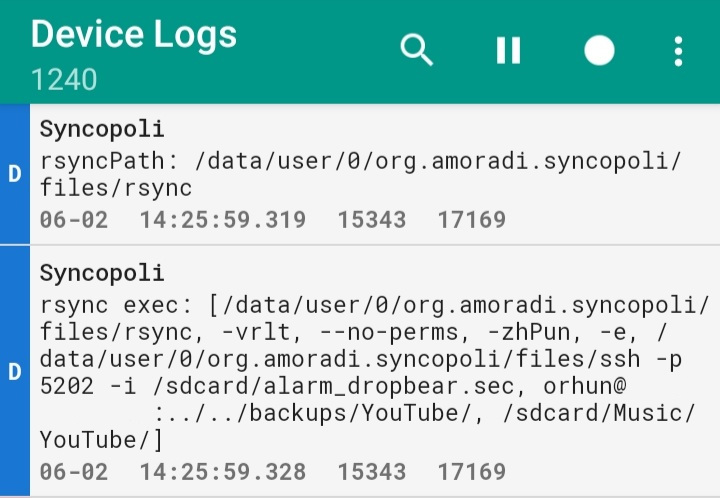
For me, the biggest challenge was to use my private key for the SSH connection. To do that, you need to convert your key to dropbear format:
$ dropbearconvert openssh dropbear <openssh_private_key> <dropbear_output_file>But even though I did this, I still couldn't connect:
userauth_pubkey: signature algorithm ssh-rsa not in PubkeyAcceptedAlgorithms [preauth]
I solved this issue by adding the following line to my /etc/ssh/sshd_config and restarting sshd:
PubkeyAcceptedKeyTypes=+ssh-rsaThen everything worked perfectly and I managed to transfer files to my phone.

Here is what my sync profile looks like:
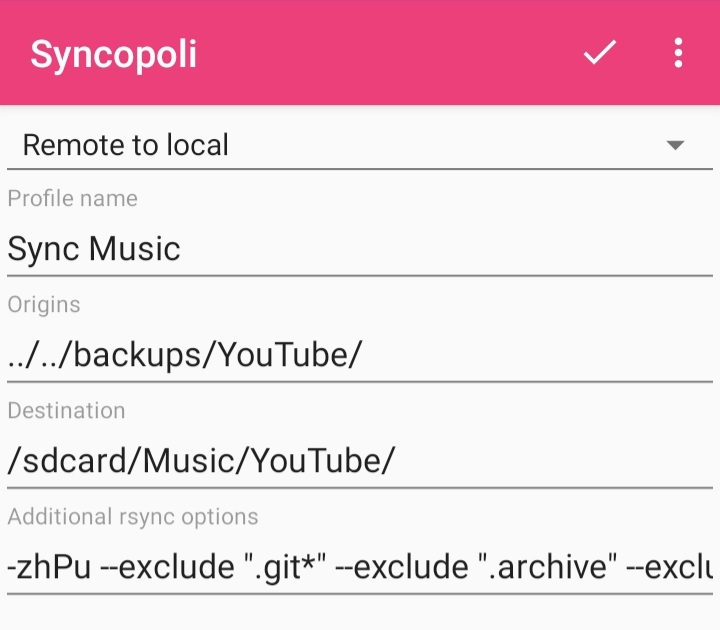
JSON export:
{
"version": 2,
"globals": {
"pref_key_server_address": "<server>",
"pref_key_protocol": "SSH",
"pref_key_username": "orhun",
"pref_key_rsync_password": "",
"pref_key_options": "-vrlt --no-perms",
"pref_key_private_key": "/sdcard/alarm_dropbear.sec",
"pref_key_port": "<port>",
"pref_key_frequency": "12",
"pref_key_ssh_password": "",
"pref_key_wifi_only": true,
"pref_key_wifi_name": "",
"pref_key_as_root": ""
},
"profiles": [
{
"name": "Sync Music",
"sources": ["../../backups/YouTube/"],
"destination": "/sdcard/Music/YouTube/",
"rsync_options": "-zhPu --exclude \".git*\" --exclude \".archive\" --exclude \"*.sh\"",
"direction": "INCOMING"
}
]
}I had to use ../../ for the origin directory since rsync is launched from $HOME as default. Maybe there is another way to achieve this but this worked well so I didn't look into other options. If you know a better way, let me know!
Tweaking rsync settings
The default arguments that are passed to rsync are the following:
--verbose, -v: increase verbosity--recursive, -r: recurse into directories--links, -l: copy symlinks as symlinks-times, -t: preserve modification times--no-perms: do not preserve permissions
Additionally, I'm using the following flags/arguments:
--compress, -z: compress file data during the transfer--human-readable, -h: output numbers in a human-readable format-P: equivalent to--partial --progress. Its purpose is to make it much easier to specify these two options for a long transfer that may be interrupted.--update, -u: skip files that are newer on the receiver--exclude=PATTERN: exclude files matching PATTERN
Keep in mind that you can use --dry-run, -n flag to perform a trial run. It is also a good idea to create another profile on Syncopoli for dry-run.
I also suggest having albums and long mixes in a separate playlist so that you can --exclude them with rsync to avoid long download times.
Listening to music 🎶
After going through all these steps and automating the download/sync process, there is one simple thing left to do: feed your soul with music via Music Player GO!
And there you have it, an alternative approach to how you can enjoy listening to music offline while actually owning the data.
Consider supporting me on GitHub Sponsors or Patreon :3
Take care!